Data Engineering Components: dbt Explained
Note: This article is based on my personal understanding of the dbt courses I’ve completed, including Data Engineering Zoomcamp’s Week 4: Analytical Engineering, DataCamp’s Introduction to dbt, and dbt Learn’s dbt Fundamentals and Advanced Deployment.
In the data engineering world, one of the primary focuses is to gather data from various sources—such as OLTP databases (whether on-prem or cloud) and SaaS services (like Stripe Payment, Shopify Order Details, etc.)—in order to prepare it for future business use. This process is also known as ETL: Extract, Transform, Load.
However, as you may imagine, using this approach may result in back-and-forth revisions. For example, what if we defined transformation logic last month but need to modify it this month? In an ETL flow, this would mean we have to retransform and reload the data.
How can we avoid this? This is where Data Build Tool (dbt) comes in.
What is dbt
Instead of writing transformation logic ahead of time, dbt allows you to work directly on top of your data warehouse and define your transformation logic in a modular, maintainable way.
dbt doesn’t own your data or your transformation logic—it runs on top of your data warehouse. You provide the credentials of your data warehouse, and dbt knows where to run your models. Your code (including SQL queries—in dbt, they are called models—and relevant configurations) is safely stored in your GitHub repository.
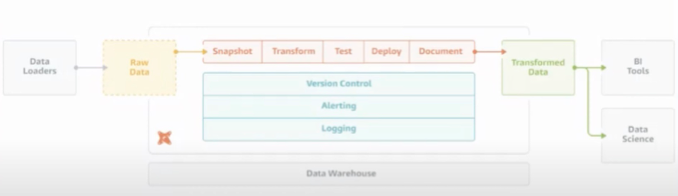
Picture source: dbt Youtube Channel
Benefits of Using dbt
Let’s delve deeper into the benefits of using dbt instead of storing transformation logic queries in different locations.
Version Control
Imagine we have many SQL queries and multiple colleagues working on them—it might be difficult to track changes. dbt allows developers to work on separate branches for better version control.
Infer Dependencies
When queries are stored separately, it becomes hard over time to remember the correct order in which to run them—even with manual notes. dbt automatically infers dependencies, reducing human error.
Data Quality
Everyone can write bad code, and we certainly don’t want that to disrupt our data analysis workflow or lead to flawed decisions. Therefore, dbt introduces testing capabilities—not only built-in tests (e.g., unique, not null) but also custom logic tests to help maintain data quality.
DRY (Don’t Repeat Yourself)
Just like in other programming best practices, we strive for modularity. dbt allows you to define generic tests and macros that can be reused across models.
Multiple Environments
For development and production, we typically use different schemas. dbt can easily set environment variables and configure these settings.
Documentation
It’s important for everyone in a company to share a common understanding of how fields are used. However, writing technical documentation can be a pain point. With built-in features, you can simply add a brief description for your model or column, and dbt will generate the documentation for you.
Key Structure
Below is a typical dbt project file structure with a brief explanation of each folder. Don’t worry if these concepts seem new; we will dive deeper later:
- models: Transformation logic (SQL queries)
- tests: Custom test files
- analysis: One-off analysis queries
- macros: Reusable SQL transformation logic (similar to functions in Python)
- seeds: Processes CSV files into lookup tables (e.g., product categories, zipcode-to-name mapping)
- dbt_project.yml: Configuration for folder paths, etc., ensures that dbt knows how to structure and run.
1. dbt Model
We generally define transformation logic in SQL queries. In dbt, a file containing a single query is called a model, and we organize these SQL queries/models in the models folder. For further understanding of how the dbt team structures projects, check out this guide.
File Structure of Models
The structure of the models folder can be broken down into the following sections:
Sources: schema.yml
Depending on the data warehouse you connect to, you define the source database in a YAML file. For example, in a configuration for Google BigQuery:
- Source Name: Source name Used in dbt.
- Database: BigQuery project ID.
- Schema: BigQuery dataset ID.
version: 2
sources:
# Name used as ref in dbt
- name: jaffle_shop
# BigQuery project id
database: iconic-heading-449916-n9
# BigQuery dataset name
schema: jaffle_shop
tables:
- name: payment
models:
- name: stg_stripe_payments
description: "Payments database."
columns:
- name: created_at
tests:
- assert_order_date_later_than_2018
Staging Folder
Models in the staging folder (typically prefixed with stg_) connect to data sources and perform light transformations (e.g., querying relevant fields and preprocessing data).
Mart Folder
Models in the mart folder can be divided into three categories:
- Intermediate Models (
int_): Serve as the middle layer between staging and read models containing business logic. - Fact Models (
fct_): Produce measurable business events. - Dimension Models (
dim_): Contain descriptive details (as introduced by star schema design).
Note: A star schema is a multi-dimensional data model used to organize data in a database so that it is easy to understand and analyze. Star schemas can be applied to data warehouses, databases, data marts, and other tools. The star schema design is optimized for querying large data sets. Source
Building the Model
Instead of querying the source database directly, we reference (ref) the models we previously created. This is one of dbt’s greatest benefits—it can infer dependencies and execute models according to the Directed Acyclic Graph (DAG) order. In other words, when a model is referenced, dbt knows to execute it first.
Note: A DAG shows the order in which tasks should run, ensuring that dependent queries are executed in the correct sequence. In an orchestration tool like Airflow, you can manually define the DAG order. In dbt, dbt will infer the order to execute.
Once we have defined the models, we run dbt run to materialize them in the data warehouse. dbt compiles the SQL queries and, following the DAG order, sends and executes them in your data warehouse.
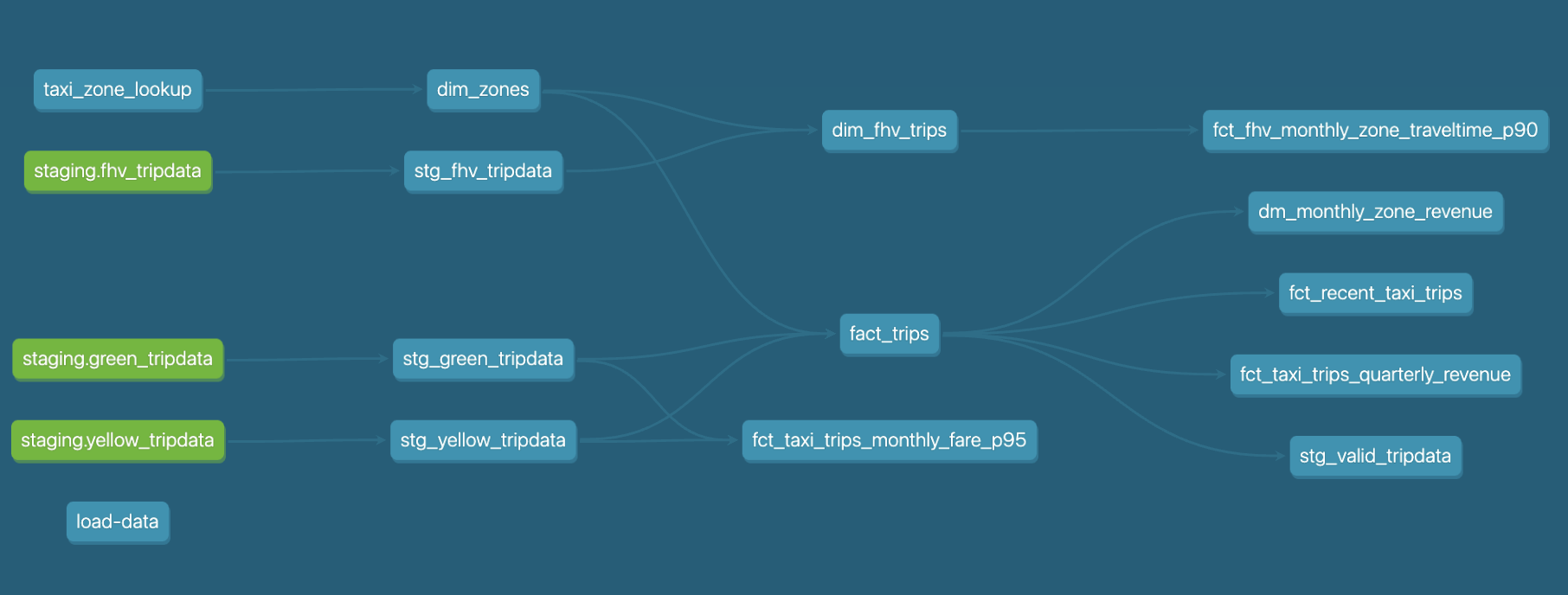
The following graph, created by the dbt doc feature (which we will explain later), shows the lineage of the models in one dbt project:
2. dbt Test
As mentioned earlier, dbt is useful for ensuring data quality. A key method to achieve this is by running tests.
Built-in Tests
Built-in tests in dbt are similar to database schema constraints (e.g., unique, not null). Other supported built-in tests include accepted values and relationships.
The following YAML explains the tests:
- ride_id: should not be null, should be unique, has a relationship with drivers.ride_id
- payment_type: should not be null, and only accept numeric values [1, 2, 3, 4, 5, 6]
version: 2
models:
- name: taxi_rides_raw
columns:
- name: ride_id
tests:
- not_null
- unique
- relationships:
to: ref('drivers')
field: ride_id
- name: payment_type
tests:
- not_null
- accepted_values:
values: [1, 2, 3, 4, 5, 6]
Custom Test: Singular Test
In addition to built-in tests, dbt supports custom data tests. The idea is to write a query that returns the rows that should not exist (i.e., failing rows).
For example, since no taxi ride should have a fare amount less than 0, you might write:
select * from where fare_amount < 0
If this query returns rows, the test fails, and you can inspect the problematic data.
Custom Test: Generic Test
If you want to verify that various columns do not contain any negative values without duplicating logic, dbt’s DRY (Don’t Repeat Yourself) philosophy allows you to define generic tests shared across columns:
{% test check_gt_0(model, column_name) %}
select *
from {{ model }}
where {{ column_name }} <= 0
{% endtest %}
Then, add the generic test in your YAML file to inform dbt:
version: 2
models:
- name: taxi_rides_raw
columns:
- name: total_fare
tests:
- check_gt_0
- name: taxi_rides_2024
columns:
- name: tips
tests:
- check_gt_0
It’s also possible to test across two columns. For example, the following query and YAML demonstrate how to compare two columns:
{% test check_columns_unequal(model, column_name, column_name2) %}
select *
from {{ model }}
where {{ column_name }} = {{ column_name2 }}
{% endtest %}
version: 2
models:
- name: taxi_rides_raw
columns:
- name: order_time
tests:
- check_columns_unequal:
column_name2: shipped_time
Running the Tests
There are two ways to run tests:
- By test name:
dbt test --select test_name:columns_equal - By model name:
dbt test --select model:taxi_rides_rawSimilar to
dbt run,dbt testexecutes according to the DAG order. If an earlier test fails, the testing process will terminate.
Bonus: Combining Run and Test Together
If you run dbt run first and then dbt test later, a model that fails its tests will require you to modify and re-run it.
To streamline this process, dbt offers the dbt build command, which runs tests immediately after materializing a model—before proceeding to the next one. For example, after materializing model A, dbt will run the tests for model A, and once successful, it will move on to the next step.
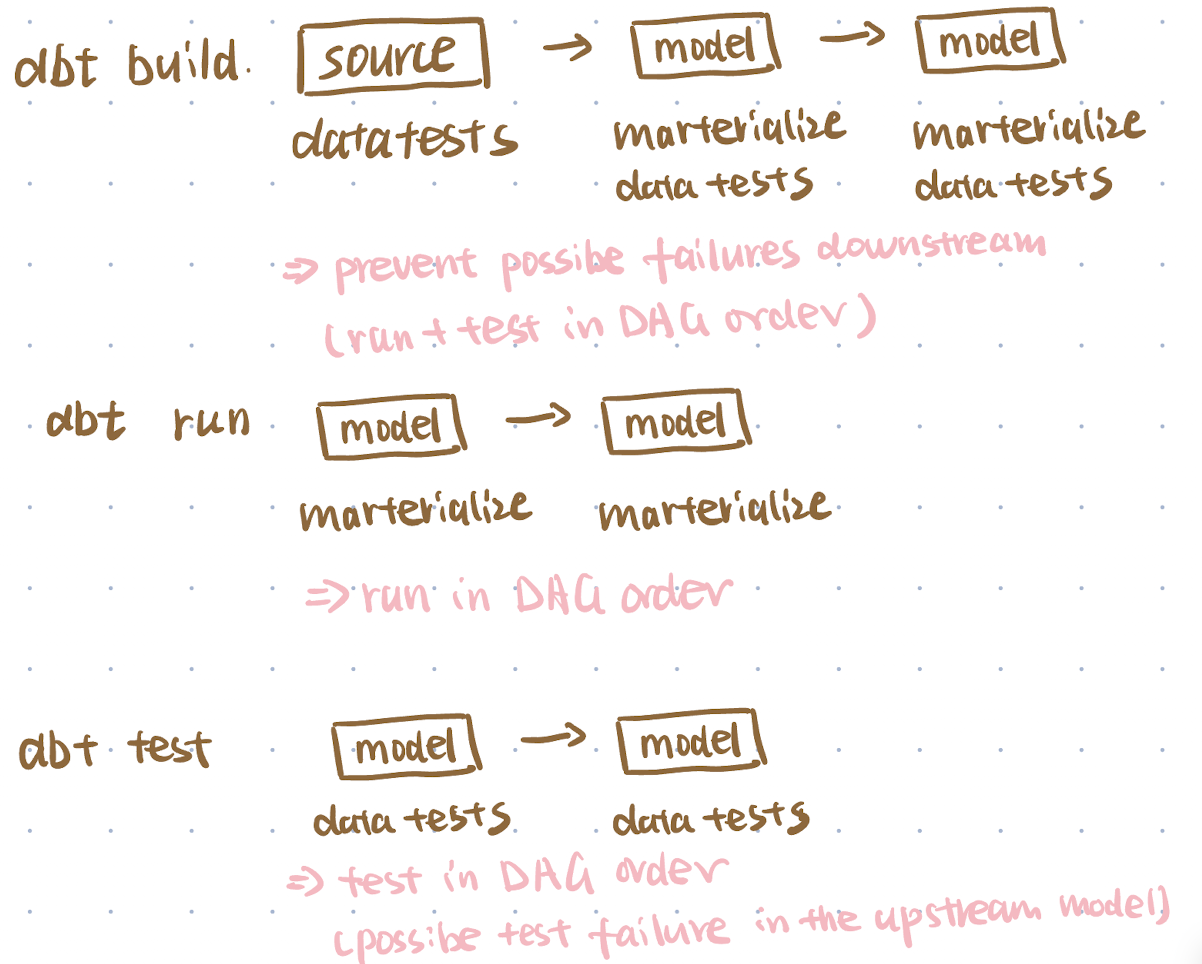
3. dbt Deployment
Deployment involves moving code to production—essentially, running a set of commands (e.g., dbt build, dbt run, dbt test), which are also called jobs in dbt in your production environment.
Triggering Jobs in dbt
Jobs in dbt can be triggered in three ways:
-
On a Schedule:
For example, you can set certain models to run every 30 minutes on weekdays.
Note: If one job is already running, subsequent jobs will be queued until the current job finishes. Therefore, it’s important to avoid conflicts between jobs. For example, if you plan to perform a full refresh (build the entire project) on Sunday at 5 a.m., it is better to pause any other jobs.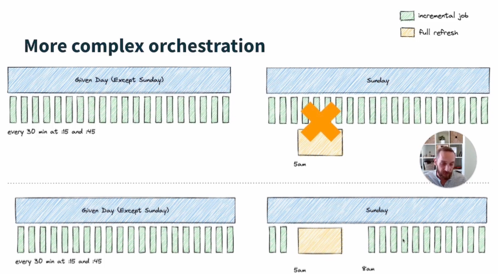
Picture source: dbt Learn - Via a Pull Request:
Using a trunk development model, developers work on separate branches and, when ready for deployment, commit and sync. When a pull request is opened, a CI (continuous integration) job can be triggered to run build and test processes. This ensures that reviewers and automatic CI checks can validate the code before it reaches production.
There are two types of CI:- General CI: Run tests on all code.
- Slim CI: Run tests only on modified models and their downstream dependencies. To use slim CI, you need to specify the command as
dbt build --select state:modified+
-
Using External Orchestration Tools:
You can also trigger jobs using external orchestration tools like Airflow. For more details, refer to this guide.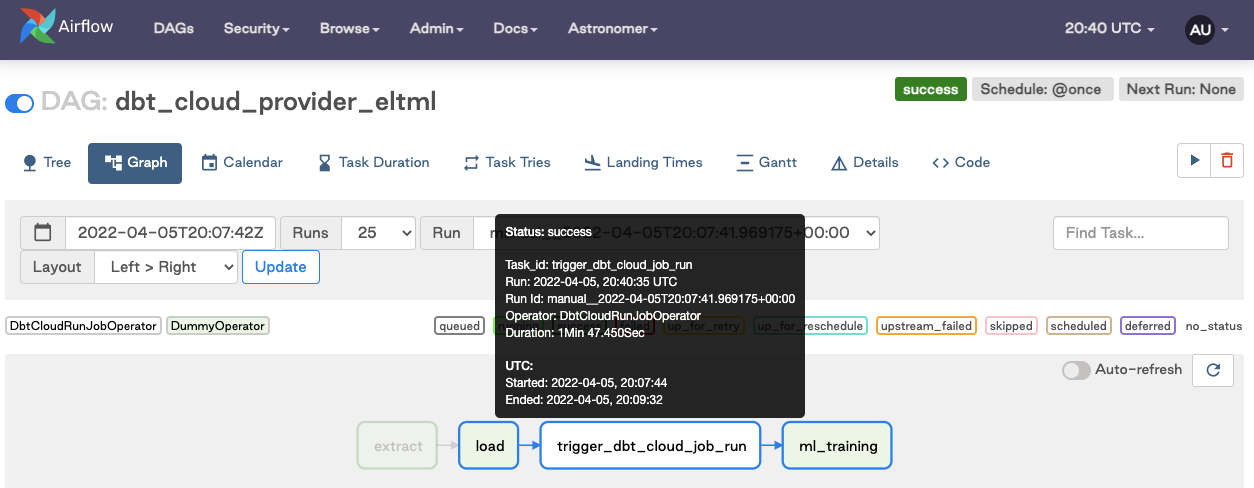
Environment Variables
Imagine you have a large dataset, but before working on it, you want to try a smaller dataset. Additionally, in a team setting, if one developer modifies a view in the data warehouse, each developer should work on separate data sources to avoid conflicts.
This is where environment variables come into play. In your profiles.yml (or the environmental configuration tab if you are using dbt Cloud), you can define two datasets:
- dev: Contains a smaller dataset.
- dev_large: Contains a larger dataset.
For example, your profiles.yml might look like this:
jaffle_shop:
# Target database
target: dev
outputs:
# Development schema
dev:
type: bigquery
method: service-account
project: your_project_id
dataset: "_preparation"
threads: 4
timeout_seconds: 300
# Larger development schema
dev_large:
type: bigquery
method: service-account
project: your_project_id
dataset: "_preparation"
threads: 8
timeout_seconds: 300
target: prod
outputs:
prod:
type: bigquery
method: service-account
project: your_project_id
dataset: jaffle_shop
threads: 8
timeout_seconds: 300
When working on the larger dataset, run:
dbt run --target dev_large
What if another developer—let’s call her Alice—also wants to run dbt run --target dev?
In dbt_project.yml, you can define:
name: jaffle_shop
version: '1.0'
config-version: 2
profile: jaffle_shop
models:
jaffle_shop:
+schema: ""
And in the schema line, you call a macro (reusable code snippets that help avoid repeating the same transformation logic stored in the marco folder) as follows:
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- elif env_var('DBT_ENV_TYPE', 'DEV') != 'CI' -%}
{{ custom_schema_name | trim }}
{%- else -%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
Assuming Alice has correctly set DBT_DEV_PREFIX as alice, her dbt run will materialize tables and views into a dataset named alice_preparation in BigQuery, and of course, no conflicts will happen.
Bonus: Environment Variable Precedence
When using environment variables, you might wonder how dbt decides which value takes priority if multiple definitions of the same variable exist.
Below is a diagram illustrating the order of precedence for environment variables in dbt:
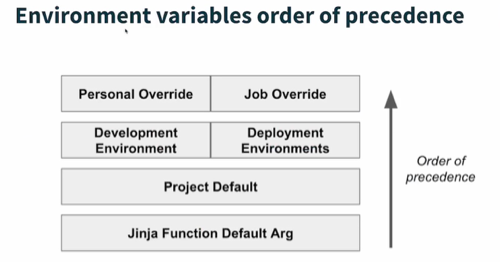
Picture source: dbt Learn
-
Personal or Job Override
For example, if you are running a dbt Cloud job, you can define variables in that job’s configuration. These overrides take precedence over any other environment variables. Jobs Override
Jobs Override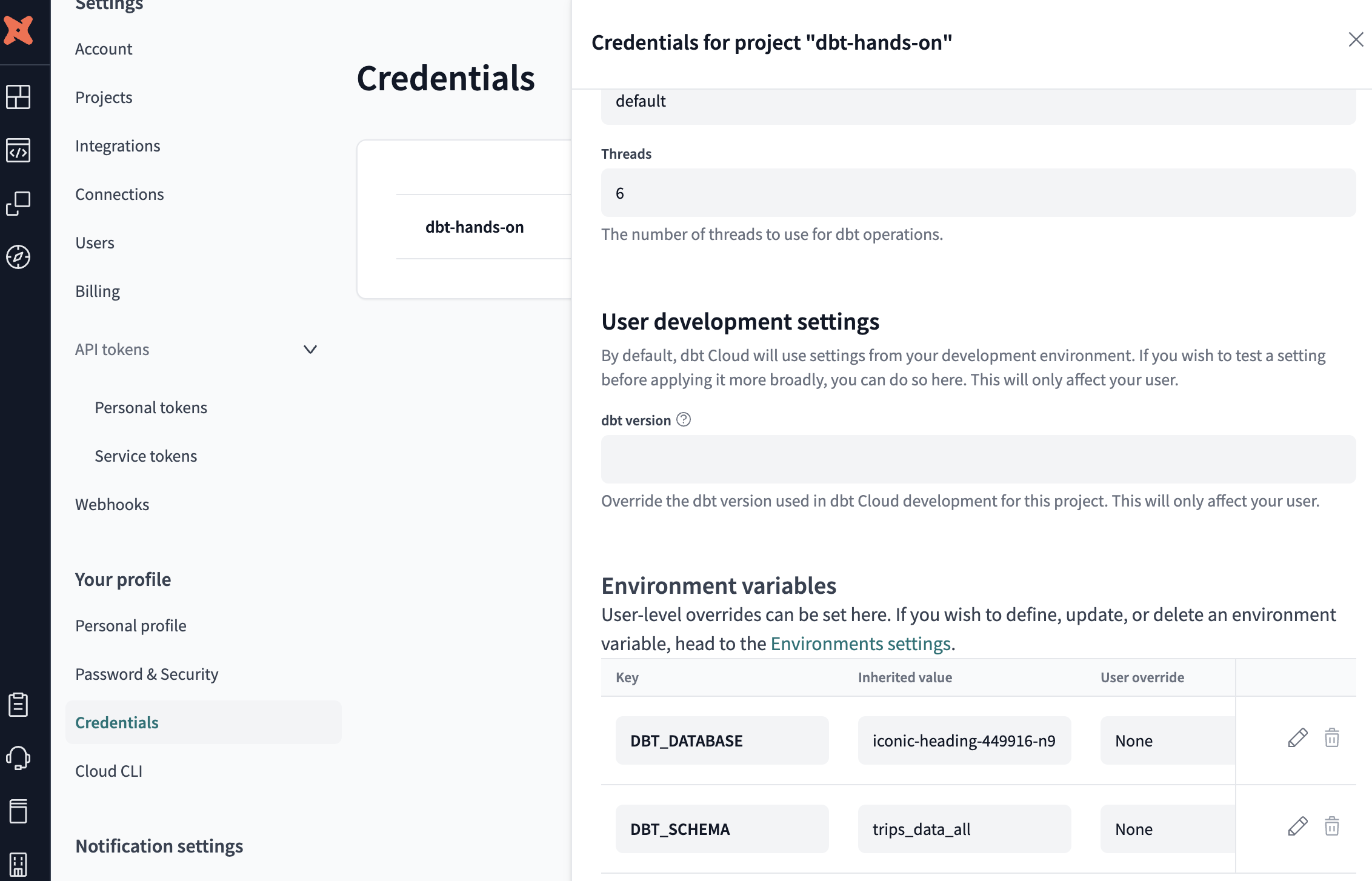 Personal Override
Personal Override -
Development Environment
Variables set in your development environment (e.g., dev environment settings in dbt Cloud). -
Project Default
Default values defined in yourdbt_project.ymlor macros. If none of the above exist, dbt uses these defaults. -
Jinja Function Default Argument
Lastly, any default argument you place directly inside a Jinja function call (e.g.,env_var('DBT_DEV_PREFIX', 'default')) is used if no other definition of that variable is found.
Check this documentation to learn more.
Example 1 from DE Zoomcamp Week 4 Homework
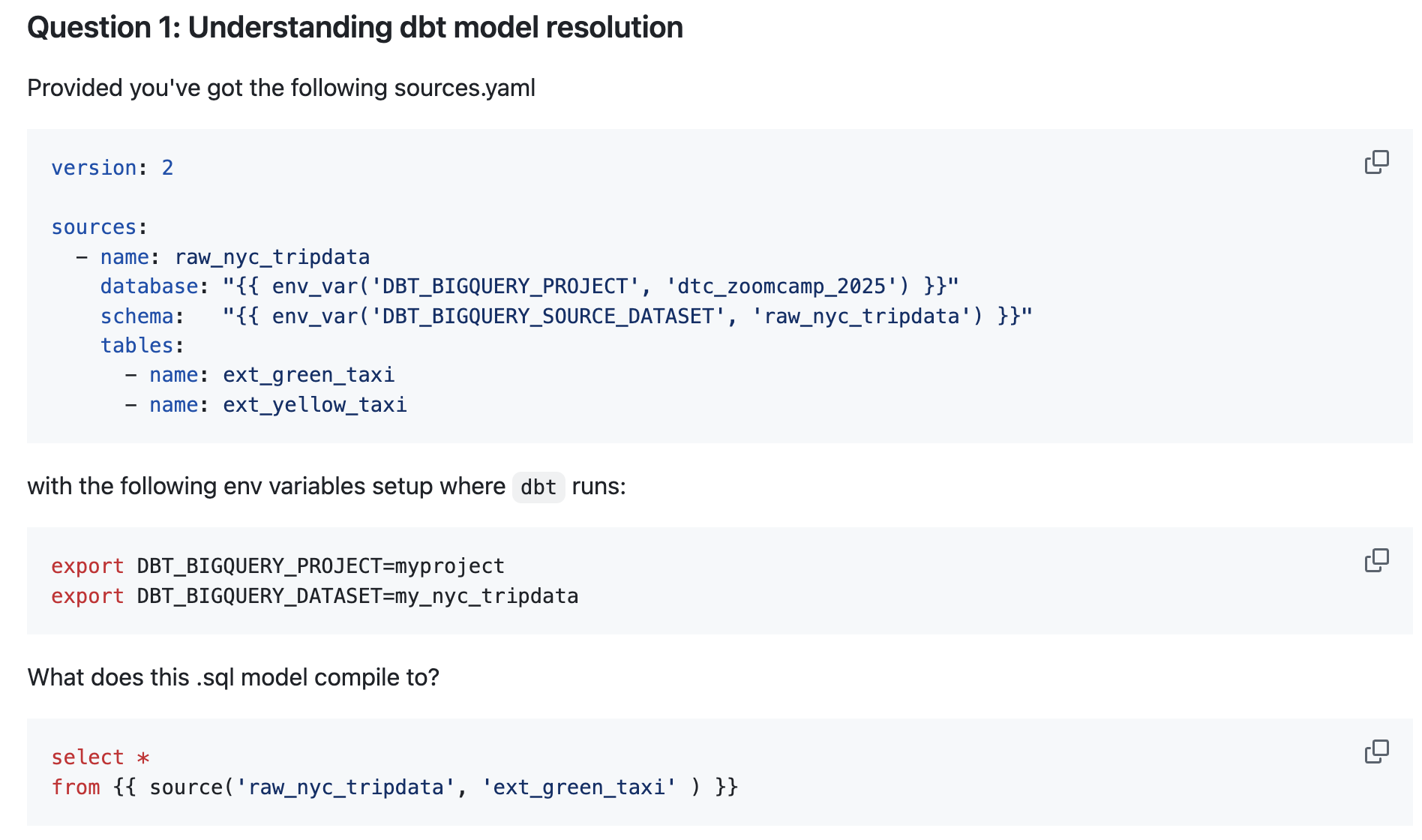 Picture source: DE Zoomcamp
Picture source: DE Zoomcamp
- There is no personal or job override mentioned here.
- We see two environment variables:
env_var('DBT_BIGQUERY_PROJECT', 'myproject')env_var('DBT_BIGQUERY_SOURCE_DATASET', 'my_nyc_tripdata')
- The project doesn’t specify a default value in the projects.yml, so this step is skipped.
- Checking the sources.yaml, which uses these Jinja functions:
- Since
DBT_BIGQUERY_PROJECTis set, there’s no need to override it. - There is no
DBT_BIGQUERY_SOURCE_DATASETdefined, so it falls back to the default valueraw_nyc_tripdata.
- Since
Therefore, the final yaml would be:
sources:
- name: raw_nyc_tripdata
# Using environment variables: DBT_BIGQUERY_PROJECT
database: myproject
# Using Jinja functions default values: DBT_BIGQUERY_SOURCE_DATASET
schema: raw_nyc_tripdata
tables:
- name: ext_green_taxi
- name: ext_yellow_taxi
Example 2 from DE Zoomcamp Week 4 Homework
Picture source: DE Zoomcamp
From the question, what we want is a personal override (command line) > environment variable > jinja default.
- We want a personal override, so the command line value takes precedence. For example, you can run:
dbt run --select fct_recent_taxi_trips --vars '{"days_back": 7}'in the development phase.
- If no command line variable is provided, then the environment variable will be used.
- The project doesn’t specify a default value in the projects.yml, so this step is skipped.
- The Jinja function needs to have a default value set, so we use:
env_var("DAYS_BACK", "30")
4. dbt Documentation
In my experience managing metadata and documentation for a large ad system, I noticed that developers often view writing documentation as a tedious task that doesn’t add value. However, maintaining coherent documentation is crucial for long-term development. For example, imagine you define product categories from 0 to 100—over time, as people come and go, someone might forget that category A was defined as number 17.
To reduce the documentation burden, dbt offers an elegant solution. Developers can simply add descriptions for models and columns in YAML:
version: 2
sources:
- name: jaffle_shop
database: iconic-heading-449916-n9
schema: jaffle_shop
tables:
- name: customers
- name: orders
models:
- name: stg_jaffle_shop__customers
description: Staged customer data from our jaffle shop app.
columns:
- name: customer_id
description: Staged customer data from our jaffle shop app.
- name: stg_jaffle_shop__orders
description: Staged order data from our jaffle shop app.
columns:
- name: status
description: ""
tests:
- accepted_values:
values:
- completed
- shipped
- returned
- return_pending
- placed
If further explanation is needed, you can create a separate doc block and reference it in the YAML file:
{% docs order_status %}
One of the following values:
| status | definition |
|----------------|--------------------------------------------------|
| placed | Order placed, not yet shipped |
| shipped | Order has been shipped, not yet delivered |
| completed | Order has been received by customers |
| return pending | Customer indicated they want to return this item |
| returned | Item has been returned |
{% enddocs %}
And when you run the dbt docs generate and dbt docs serve commands, dbt will render the doc website to allow you to easily navigate between models and columns.
5. Advanced Topic
1. How to Test and Validate the Logic on a Smaller Dataset
Imagine having a large dataset but wanting to validate your SQL logic on a smaller sample before processing the entire dataset. In addition to using a different schema, there are also two ways to do this:
- Using a Test Variable:
Add the following code block at the end of your model:By default,
is_test_runis set to true. When you execute:dbt build --select <model_name>it will only process 100 rows. After validation, run:
dbt build --select <model_name> --vars '{ "is_test_run": "false" }'to process the full dataset.
- Using dbt Cloud Interface:
If you’re using the dbt Cloud interface, the “Preview” button will run the SQL with a default 500-row limit.
2. What If I Have the Same Transformation Logic for Various Columns? - dbt macro
Imagine the original column is stored in cents, but the business department is more familiar with dollars. In a single SQL query, you might write:
select
id as payment_id,
orderid as order_id,
paymentmethod as payment_method,
status,
-- transformation logic
payment_amount / 100 as amount,
created as created_at
from
To avoid repeating the payment_amount / 100 logic, define a macro in the macros folder:
{% macro cents_to_dollars(column_name, decimal_places=2) -%}
round(1.0 * {{ column_name }} / 100, {{ decimal_places }})
{%- endmacro %}
Then, use the macro wherever needed:
select
id as payment_id,
orderid as order_id,
paymentmethod as payment_method,
status,
-- amount stored in cents, convert to dollars
as amount,
created as created_at
from
dbt will compile this into:
select
id as payment_id,
orderid as order_id,
paymentmethod as payment_method,
status,
-- amount stored in cents, convert to dollars
round(1.0 * payment_amount / 100, 2) as amount,
created as created_at
from stripe.payment
You can also reuse external libraries and macros by importing packages—check this documentation for more details.
3. From Sources to Materialization - dbt seed, dbt snapshot
Beyond databases, in real-world scenarios we often need to refer to static lookup tables (e.g., what does a particular zipcode mean?). dbt provides a function called dbt seed to help manage CSV files for lookup tables. Check the dbt seed documentation for more details.
Regarding materialization, dbt offers different methods to build your model. The most common are tables and views, though incremental and ephemeral model types are also available. Additionally, you can create snapshots to track changes in specific columns over time. See the dbt snapshots documentation for more information.
Want to Learn More?
Here are more detailed explanations of the courses I’ve completed:
- DE Zoomcamp Week 4: Explains relevant dbt concepts using the NYC taxi dataset. It’s better if you follow the previous weeks.
- Introduction to dbt: Provides hands-on experience with dbt core (the free-to-use, open-source CLI version) across models, tests, and other functions such as seeds and snapshots.
- dbt Fundamentals: Demonstrates how to build a dbt project using dbt Cloud (the commercial version). It’s really useful for setting up your first project using the dbt Quickstarts.
- Advanced Deployment: Covers detailed dbt Cloud deployment knowledge, including continuous integration (CI).
If you want to know more, especially about real-life use cases, you can check out this guide from GitLab: Using dbt. It covers onboarding materials for dbt in a real working environment, including useful tools (e.g., VS Code extensions) and detailed explanations of dbt functions (e.g., models, seeds, snapshots).
Have fun learning dbt!