Data Engineering Components: Apache Kafka Explained
Behind the Scenes: What Happens Behind Our Online Orders?
It’s quite common to buy items online. But what processes are handled behind the scenes once an order is placed?
Traditional Request–Response Model
The order service receives the customer’s request and writes a record (or row) into the order database. Then the shipping service calls the order service’s API to retrieve the relevant order details and prepare the delivery.
This pattern is known as the request–response model, since services respond only when they receive a request—either from a user or another service. However, many services depend on the order service for information—such as inventory or billing—so they all need to send requests to it. This tightly coupled design can lead to scalability challenges.
Is there a better way for the order service to simply notify everyone whenever there’s an update?
Event-Driven Model with Kafka
Here’s another architecture: the event-driven model. When an order is placed, the order service not only updates its database but also publishes an event containing all the order details to a message broker like Kafka. Any service interested in updates need only subscribe to the Kafka topic and process each event as it arrives. This pattern is also called publish–subscribe.
Kafka Basics
Topics
When using a message broker, it’s recommended to have multiple topics rather than one large topic that contains every kind of message—much like developers prefer microservices over a monolithic application, or smaller tables over one giant table. Having separate topics decouples different services, simplifies maintenance, improves scalability, and lets you manage access control more granularly for enhanced security.
For example, in our shopping scenario, when the order service receives a new purchase, it can publish an event to a billing_events topic:
{
"order_id": "12345",
"amount": 150.75,
"payment_method": "credit_card",
"timestamp": "2025-04-07T12:34:56Z"
}
The billing service processes the payment and then publishes a message to the billing_outcome topic:
{
"order_id": "12345",
"payment_status": "paid",
"transaction_id": "txn_78910"
}
Other services—like inventory and shipping—can subscribe to billing_outcome, filter for payment_status = paid, and carry out downstream steps such as updating stock and initiating shipping.
One thing to mention is that Kafka topics differ from queue services like Amazon SQS, which act as temporary buffers: once a message is consumed, it disappears. A Kafka topic is more like a durable event log—you write data to it, and it remains even after consumers have read and processed it.
Partitions
As mentioned above, topics are stored on disk. Partitions determine how that data is distributed across brokers.
Kafka assigns messages to partitions with or without a key:
-
Without a key: Messages are randomly assigned to partitions, so no ordering is guaranteed.
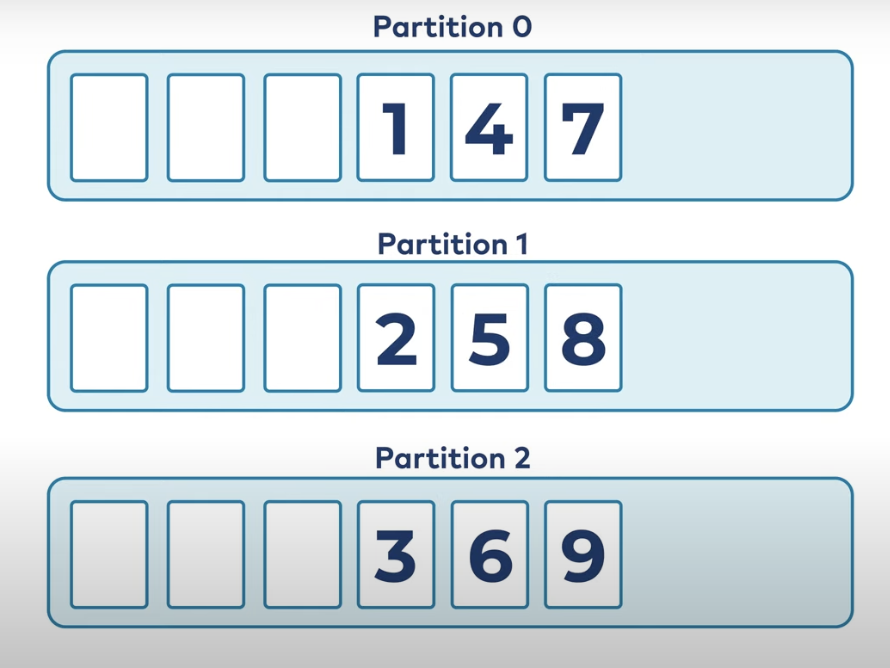 Source
Source -
With a key: Kafka hashes the key and ensures that all messages with the same key go to the same partition, preserving their order.
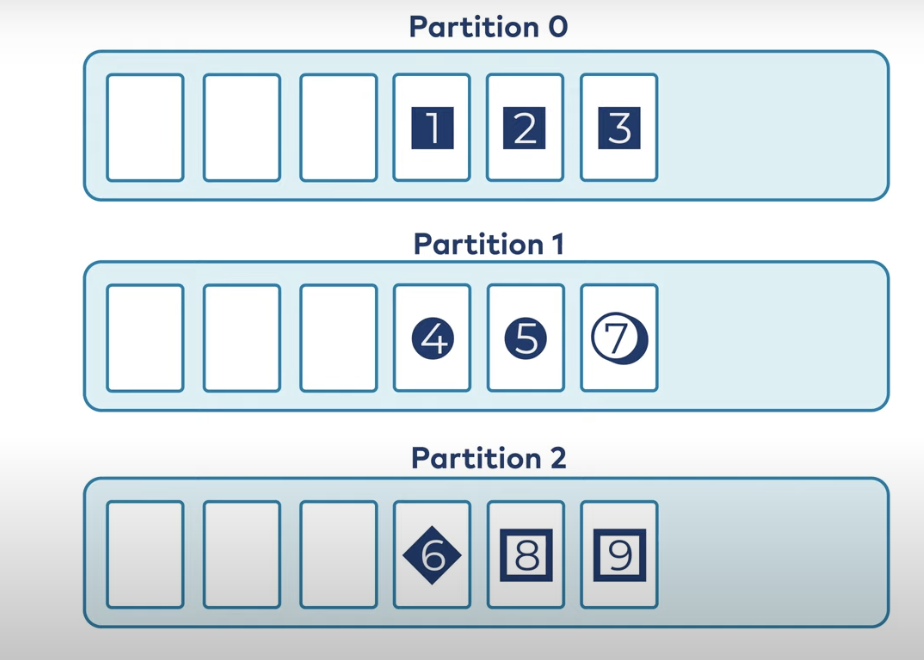 Source
Source
For example, using order_id as the key for billing_outcome events ensures all updates for that order go into the same partition:
{
"order_id": "12345",
"payment_status": "paid",
"transaction_id": "txn_78910"
}
Interacting with Kafka: Producers and Consumers
Analogy: Kafka as a Water Reservoir
Think of Kafka as a reservoir with many channels (topics):
- Producers (Publishers) are like water sources pouring data into the channels.
- Kafka Topics hold and buffer this data durably on disk.
- Consumers (Subscribers) are the taps: they connect to the channels they care about and draw data when needed.
Hello World Version
Note: If you don’t have a preconfigured environment, read through this first—we’ll cover installation later.
To produce messages via the console:
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic hello_world
Type any message (e.g., hello world), then press Ctrl+C to exit.
To consume the messages you’ve produced:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic hello_world --from-beginning
Again, press Ctrl+C to exit.
Write Your Own Code Version
Producer
Using Python, you can produce the same messages:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
topic_name = 'hello_world'
try:
while True:
message = input("> ")
if message:
producer.send(topic_name, value=message.encode('utf-8'))
print(f"Sent: {message}")
except KeyboardInterrupt:
print("\nExiting...")
finally:
producer.flush()
producer.close()
You can also stream rows from a CSV file:
import json
import pandas as pd
from kafka import KafkaProducer
def json_serializer(data):
return json.dumps(data).encode('utf-8')
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=json_serializer
)
topic_name = 'green_tripdata'
columns = [
'lpep_pickup_datetime',
'lpep_dropoff_datetime',
'PULocationID',
'DOLocationID',
'passenger_count',
'trip_distance',
'tip_amount'
]
df = pd.read_csv('/opt/src/green_tripdata_2019-10.csv', usecols=columns)
for _, row in df.iterrows():
message = row.to_dict()
producer.send(topic_name, value=message)
Consumer
Consume data with Python:
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'hello_world',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
group_id='consumer-group-1'
)
for message in consumer:
print("Received message:", message.value.decode('utf-8'))
Key feature: By assigning a group_id, multiple consumer instances can form a group. Kafka will distribute partitions among them for horizontal scaling.
 Source: Confluent Developer
Source: Confluent Developer
Connector Version
Kafka’s ecosystem shines with connectors, which let you integrate with external systems via configuration instead of custom code.
Producer: Source Connector
On the producer side, use a source connector (e.g., the JDBC connector or Debezium PostgreSQL connector) to capture database changes and stream them into Kafka topics.
- Download and unzip the connector.
- Place it in the Kafka Connect plugin directory (
plugin.path). - Configure and start it:
confluent local services connect connector load jdbc-source \
--config $CONFLUENT_HOME/share/confluent-hub-components/\
confluentinc-kafka-connect-jdbc/etc/source-quickstart-sqlite.properties
You should see a successful startup message. Then consume from the topic:
./bin/kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--topic test-sqlite-jdbc-accounts \
--from-beginning
Consumer: Sink Connector
On the consumer side, use a sink connector (e.g., S3 Sink Connector) to write messages from Kafka topics into external stores like Amazon S3.
confluent local services connect connector load s3-sink
{
"name": "s3-sink",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"tasks.max": "1",
"topics": "s3_topic",
"s3.region": "us-west-2",
"s3.bucket.name": "confluent-kafka-connect-s3-testing",
"s3.part.size": "5242880",
"flush.size": "3",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"format.class": "io.confluent.connect.s3.format.avro.AvroFormat",
"schema.generator.class": "io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"schema.compatibility": "NONE",
"name": "s3-sink"
}
}
Then start Kafka Connect:å
confluent local services start
Any messages in your topic will be saved to the specified S3 bucket.
Note: The source connector uses the Producer API under the hood, while the sink connector uses the Consumer API—both leverage the Kafka Connect framework.
Inside Kafka: Architecture
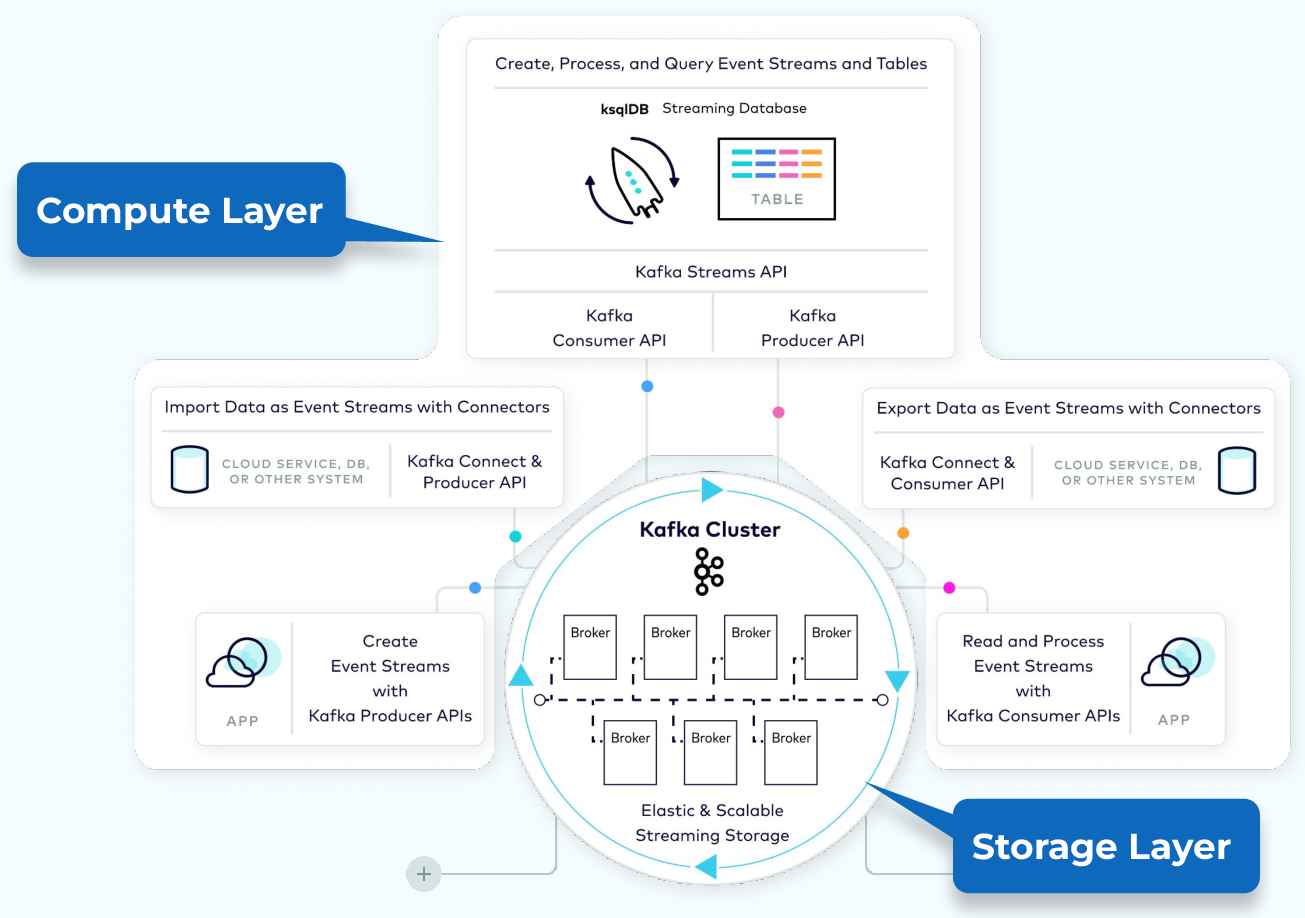
In this architecture diagram, the producer, consumer, and connectors all interact with Kafka storage. What does that storage layer look like?
Storage Layer: Broker
Partitions are virtual divisions, but they’re stored on brokers—servers or machines running Kafka. In production, you’ll typically deploy multiple brokers in a cluster to distribute load and ensure high availability.
 Source: Udemy course: Apache Kafka
Source: Udemy course: Apache Kafka
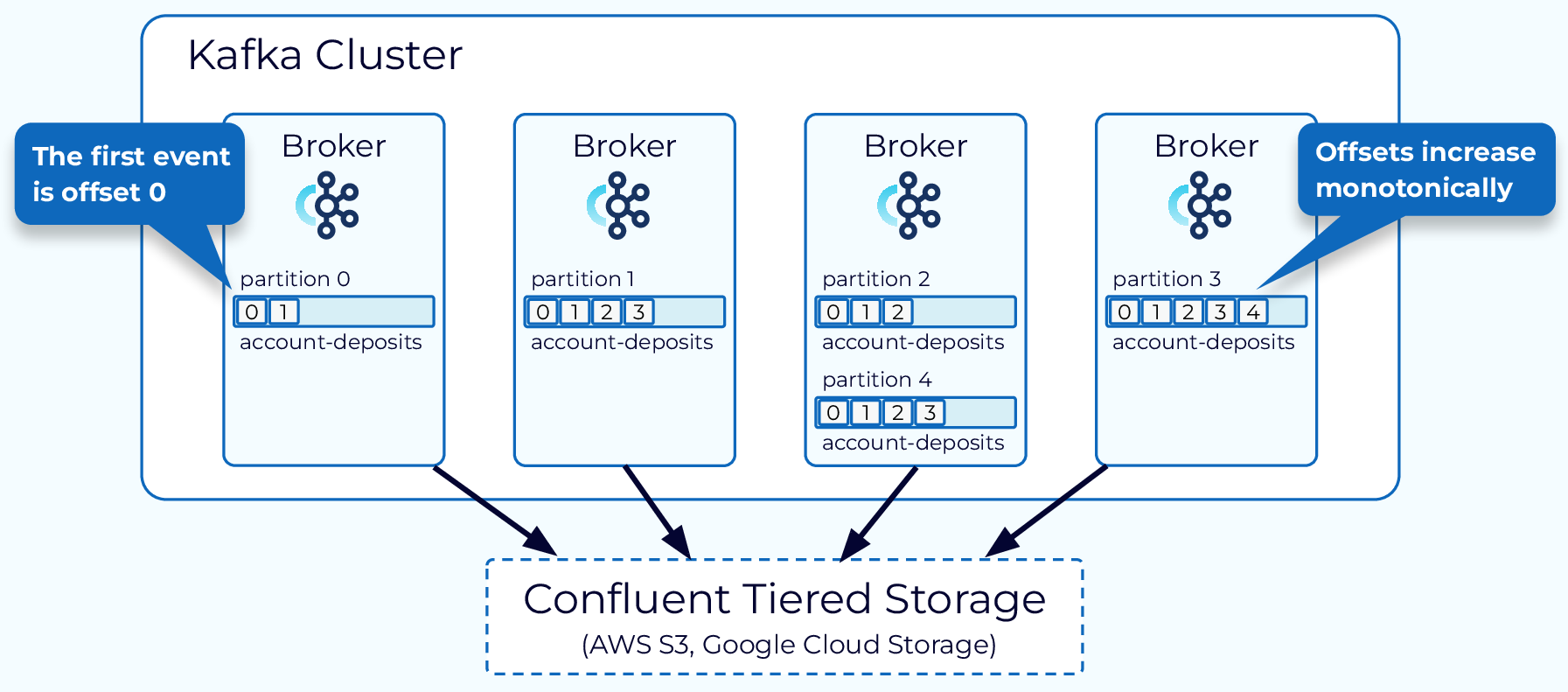
The remaining parts (like replication) will be updated in a future version.
Want to Learn More?
You can start with What is Event-Driven Architecture and What is Kafka to get a general understanding of EDA and Kafka.
Then, follow the Confluent course Kafka 101 to dive deeper and get hands-on experience.
Useful resources for the Kafka Connect part:
- Check out Kafka Connect 101 to learn the basics and how to deploy it.
- Confluent Connectors Hub: https://www.confluent.io/hub/. If a connector has a Self-Hosted version and is under the Confluent Community License, it means you can at least run it in your local environment without needing to use Confluent Cloud.
- Connector installation guide: https://docs.confluent.io/platform/current/connect/install.html
For a comprehensive learning experience, check out this Udemy course.